How to train intents
There are two ways to make the bot understand natural language by using intents:
-
Patterns — formal rules for matching requests against special templates. For example, if a request matches a pattern like
{(~fix/~mend/repair*/recover*/servic*) * (pc/laptop [pc]/computer)}, chances are high that the user is asking where they can have their computer fixed. -
Training phrases — example requests used for training the classifier. For example, the bot can be trained to recognize the same intent based on training phrases like I need to fix my computer, where can I have my pc mended, we are looking for a macbook service shop.
Compared to patterns, training phrases can significantly reduce the overhead associated with NLU training: you don’t have to write any rules by hand nor try to make them include as many synonyms as possible. You can use external conversation log files as your source of training phrases, as well as annotate phrases directly from dialog analytics after the bot has been launched.
On the other hand, non-rule-based algorithms are arguably less transparent than their counterparts, which makes the use of training phrases more unpredictable. If you decide to use them for training, bear in mind the specifics of how a particular classifier algorithm works and follow a few simple rules when preparing the training set.
What’s the difference between classifier algorithms
The training set requirements will be different depending on the classifier algorithm selected in project settings.
STS
STS (Semantic Textual Similarity) is an algorithm that compares the semantic distance between words. It takes into account inversion, dictionary forms of words, their synonyms, and other information.
Advantages of STS:
- It performs well on small datasets: even if each intent contains only one training phrase, the algorithm will work.
- It allows you to use entities in training phrases.
- It is not sensitive to the imbalanced distribution of phrases across intents.
- It distinguishes between semantically similar intents better than Classic ML.
- It has the most flexible and interpretable settings.
Use advanced NLU settings to adapt the algorithm to your project.
For example, use the
synonymMatchparameter to regulate the weight of synonym matches.
Classic ML
Classic ML is a standard machine-learning algorithm for logistic regression-based intent recognition.
Advantages of Classic ML:
- It maintains a good performance under high bot load conditions.
- It takes into account dictionary forms (lemmas) and word stems.
Deep Learning
Deep Learning is an algorithm based on convolutional neural networks. It relies on semantic information when calculating similarity scores and, unlike Classic ML, takes synonyms into account.
Advantages of Deep Learning:
- It performs well on large datasets.
- It distinguishes between similar intents better than Classic ML.
Transformer
Transformer is a multilingual algorithm. It evaluates the semantic similarity of the user request with all the training phrases from the intent.
Advantages of Transformer:
- It performs well on small datasets.
- It can recognize languages other than those supported by JAICP.
- It is based on a large language model and compares phrase vectors, operating on the meaning of whole phrases rather than separate words.
- It is case-sensitive and takes into account punctuation marks.
How many phrases per intent should there be
The number of intents the classifier should support and the optimal number of training phrases per intent are in direct relation to the algorithm used.
- STS needs 5–7 training phrases per intent, but no more than 1,000 phrases in the whole dataset to maintain the optimal response speed.
- Classic ML needs at least 20 training phrases per intent. The larger the dataset, the more accurate the classifier will be.
- Deep Learning needs at least 50 training phrases per intent. The larger the dataset, the more accurate the classifier will be.
- Transformer needs at least 10 training phrases per intent. The larger the dataset, the more accurate the classifier will be.
The recommended length of a training phrase is 1–10 words. It is harder to extract meaning from a long phrase, which is why it is a bad example for determining an intent.
It is important to keep the training data distributed evenly across intents. For example, all intents should have at least 20 phrases (Classic ML) or at least 50 (Deep Learning).
How to prepare a training set
If the contents of the intents are similar, user requests may not be recognized correctly. To ensure that requests trigger the right intents, you need to prepare a high-quality training set that doesn’t contain duplicates, similar phrases, and stop words.
Set up the search for matches
To avoid having duplicates and similar training phrases and answers in your intents, enable the search:
- Go to the JAICP main page and find the project you need in the My projects section.
- Click in the project card → select Project settings.
- Find the Search for matches setting on the Classifier tab and enable it. By default, training phrases can match by 50% and answers by 80%.
The search for matches is triggered when you enter new training phrases and answers, as well as when you edit them.
Whenever you save a phrase, it’s classified. If the phrase is similar enough to other intents, you’ll get a warning with a list of those similar intents.
Whenever you save an answer, it’s compared to answers from other intents by the Jaccard index.
Here’s an example of how you could use the search for matches:
Create an /I want to buy the course intent. Fill it with training phrases and type a response to it:
- Phrases
- Answer
- I’m interested in this training course
- I need to buy your course
- I’d like to purchase this course
- I’m buying your education course
For more information about courses, visit https://example.com/
Click Test to train the classifier. The contents of the intent will be taken into account when searching for matches in other intents.
Now, create an /I want to make a refund intent and fill it out.
By default, phrases can match by 50% and answers by 80%. If these values are exceeded, warnings will appear:
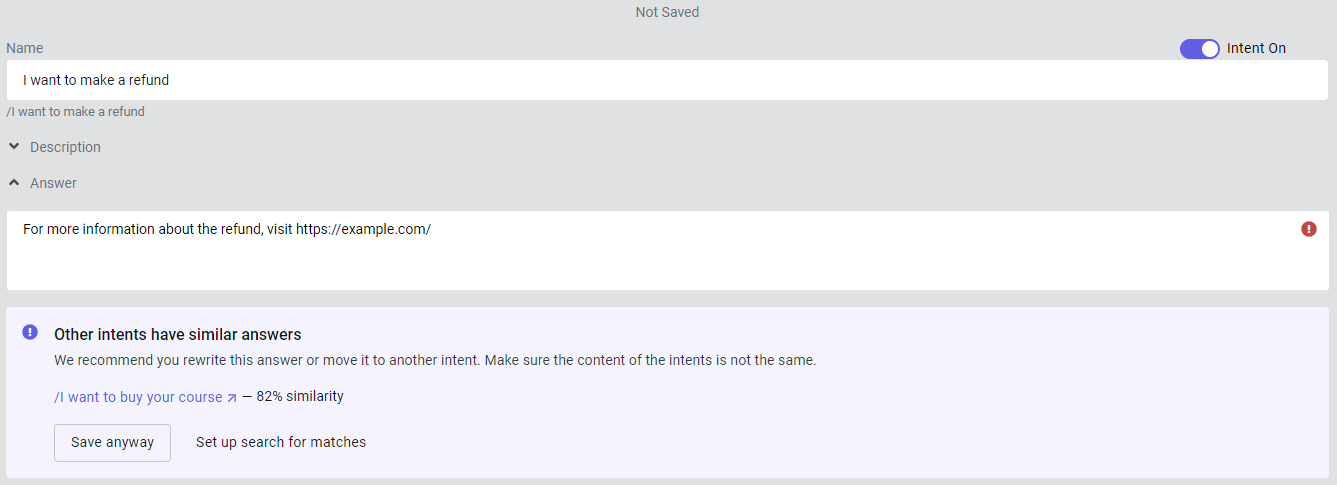
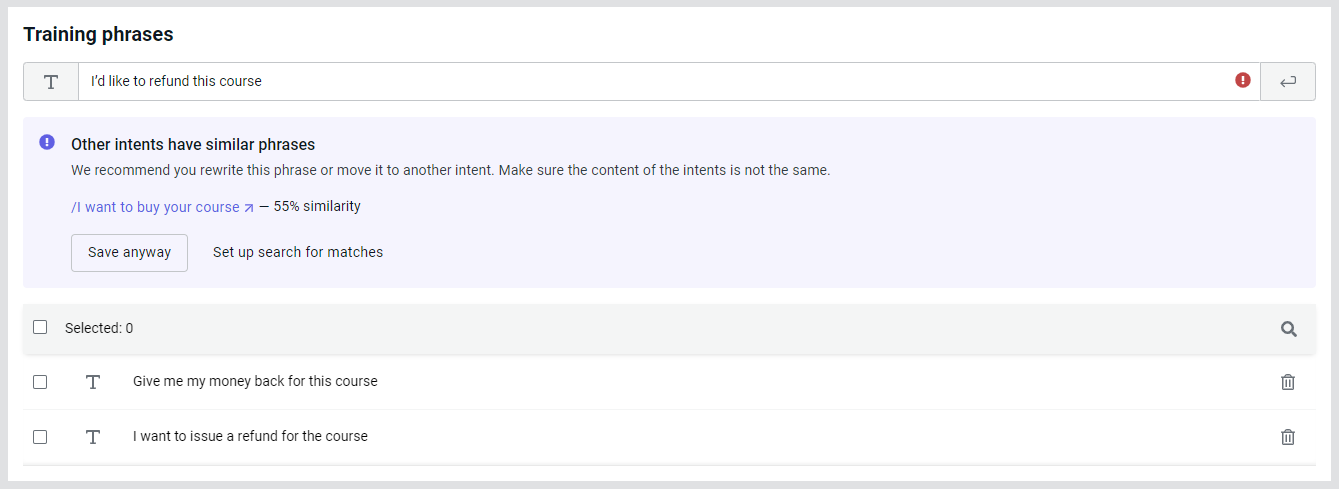
You can:
- Save anyway — ignore the classifier’s warning and save your phrases and answers anyway. Some intents may be too similar, lowering the quality of the training set.
- Set up search for matches — adjust the classifier settings and find the optimal values for your project.
Remove duplicates
Both Classic ML and Deep Learning are sensitive to duplicate training phrases in intents. This can be observed by taking the following steps:
- Create a new project and select Deep Learning as the classifier in the project settings.
- Go to NLU → Intents and select the hello intent. It should have one training phrase: hello.
- Click Test and enter a query with a similar meaning, like hello everyone.
- Close the test widget, add another hello to the intent training set, and repeat step 3.
After you added a duplicate, the similarity score of the same request has increased.
On the other hand, STS and Transformer calculate the semantic similarity of the request to each training phrase individually. If you carry out the same experiment with an STS or Transformer project, it will be evident that these algorithms are insensitive to training phrase duplicates and doesn’t increase the score of such intents. Nonetheless, it’s generally best to do without them at all.
Avoid similar training phrases
When preparing the training set, even more important to avoid than duplicates are training phrases different only in a couple of words or having a different word order.
- Good training set
- Bad training set
- could I arrange a meeting with my manager
- I need to see my managing director
- I would like to make an appointment with my manager at 5
- can you plan a session with my boss tonight
- could I arrange a meeting with my manager
- could I arrange a meeting with my boss
- could a meeting with my manager be arranged
- a meeting with my manager at 5
Phrases from the bad training set contain the same words and express the intent in only one way. If these phrases are used for training, the model will become overfitted: the intent will only be triggered by phrases closely matching those in the training set, but not by others.
Filter out stop words
It is good practice to remove stop words from training phrases, meaning high-frequency common words which may occur in phrases on any subject.
Avoid situations when stop words are distributed unevenly across intents. Otherwise it is typical to run into the following issue: a request containing stop words can trigger the wrong intent which has the same stop words in the training set, while the correct one has a lower score.
Some of the most frequent stop words include:
- Greetings and farewells like hello, goodbye
- Words of entreaty and appreciation like please, thank you
- Modal words like may, want
- Whole phrases like I have a question, can you clarify an issue
You can reuse open-source stop word dictionaries
(for example, take one from one of the stopwords-iso project repositories)
and extend them with words specific to your dataset.