Разметка логов
Разметка логов используется для обработки «сырых» логов, чтобы выделить в них потенциальные интенты и наполнить их тренировочными фразами. Она будет полезна, если у вас есть собственные данные, которые можно использовать для обучения бота. Если их нет, но бот уже какое-то время проработал и накопил данные о диалогах, дообучите интенты.
Чтобы получить доступ к разметке логов, свяжитесь со своим аккаунт-менеджером или напишите нам на contact@just-ai.com.
Чтобы воспользоваться разметкой логов:
-
Перейдите в проект и на панели управления нажмите NLU → Разметка логов.
-
Если ранее вы уже пользовались разметкой логов, нажмите Новый набор фраз.
-
Подготовьте файл с фразами, которые хотите обработать.
- Требования к файлу: формат TXT, кодировка UTF-8.
- Внесите в файл не более 10 000 фраз.
- Расположите каждую фразу на отдельной строке.
- Сократите фразы длиннее 500 символов, или они будут удалены.
-
Прикрепите файл.
После загрузки файла фразы появятся в разделе Все фразы.
Чтобы наполнить новые и уже существующие интенты загруженными фразами:
- Предобработайте фразы.
- Воспользуйтесь методами разметки.
- Распределите фразы по интентам.
- Сохраните их в интенты.
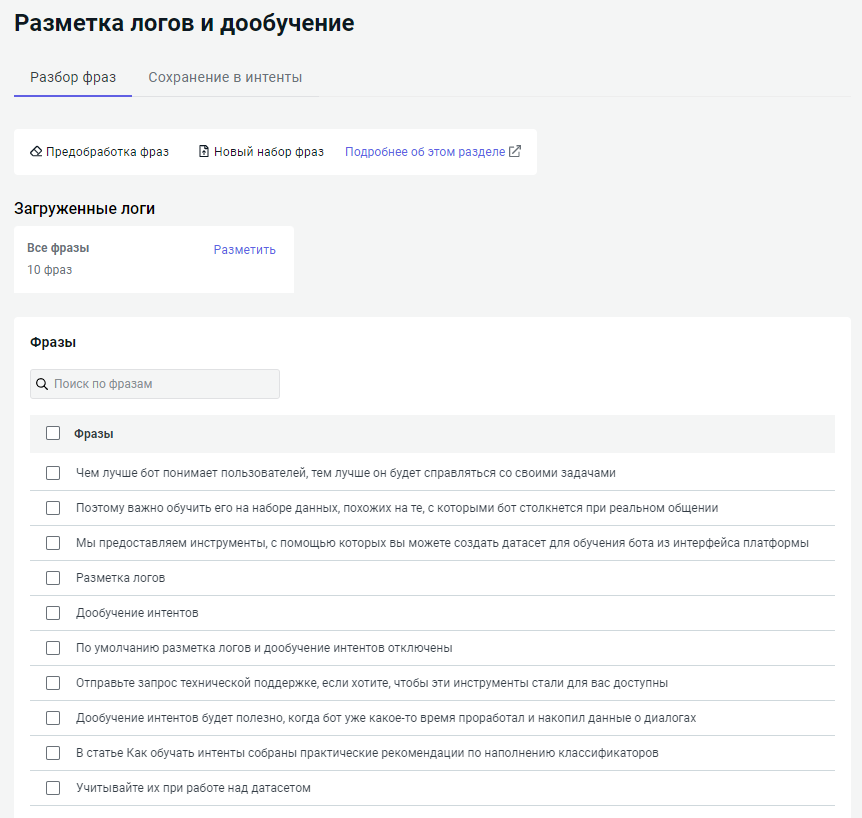
Предобработка фраз
Чтобы распределять фразы по интентам было проще, необходимо предварительно их обработать:
-
Перейдите на вкладку Разбор фраз → Предобработка фраз.
-
Настройте параметры:
- Удалить специальные символы — удаление всех символов, кроме букв и цифр.
- Удалить короткие фразы — удаление всех фраз короче указанного числа знаков с учетом пробелов.
- Удалить длинные фразы — удаление всех фраз длиннее указанного числа знаков с учетом пробелов.
- Исправить опечатки — исправление орфографических ошибок и опечаток. Параметр включен по умолчанию и доступен только для русского и украинского языков.
- Удалить стоп-слова — словарь стоп-слов встроен в платформу и доступен только для русского языка.
- Распознать сущности —
поиск активных системных и пользовательских сущностей во фразах.
Например: «завтра в 16:00» будет заменено на «завтра в
@duckling.time». - Удалить дубликаты — после удаления останется только одно вхождение для каждой фразы. Параметр включен по умолчанию. ? > Если вы хотите перед удалением просмотреть дубликаты, отключите этот параметр и воспользуйтесь разметкой по дубликатам.
-
Нажмите Обработать.
Методы разметки
Если вы обрабатываете большой объем фраз, методы разметки помогут сгруппировать их, чтобы упростить распределение фраз по интентам. Для этого на вкладке Разбор фраз в разделе Загруженные логи нажмите Разметить и выберите метод разметки.
Вы можете разметить фразы:
После разметки датасета распределите фразы по интентам.
Вы также можете распределить фразы по интентам вручную:
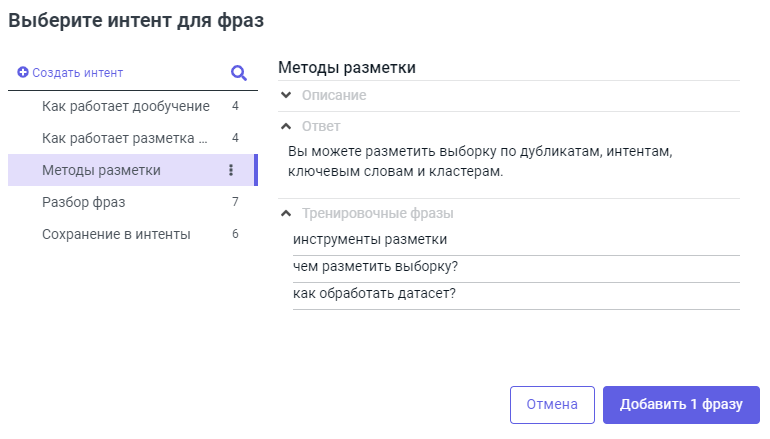
-
Выберите фразу или несколько фраз и нажмите Добавить в интенты. Появится окно выбора интента.
-
Выберите подходящий интент или создайте новый. После этого нажмите Добавить фразу.
-
Перейдите на вкладку Сохранение в интенты на верхней панели, чтобы подтвердить добавление.
По интентам
Эта разметка позволяет разобрать фразы по интентам, которые уже существуют в проекте.
Каждой распознанной фразе присваивается вес от 0 до 1 — это степень уверенности в том, что она действительно содержится в интенте. Чтобы отфильтровать фразы по весу, воспользуйтесь ползунком.
По дубликатам
Эта разметка позволяет выделить в датасете одинаковые фразы. Если вы удаляли дубликаты во время предобработки фраз, эту разметку проводить не нужно.
По ключевым словам
Эта разметка позволяет выделить во фразах ключевые слова и сгруппировать по ним датасет.
Методы выделения ключевых слов:
- Частотный на основе меры TF-IDF.
- Синтаксический, который использует парсер UDPipe.
Частотный метод
Мера TF-IDF позволяет оценить значимость слова в контексте фразы и всего датасета. Чем важнее слово для определения тематики фразы внутри датасета, тем больше значение меры.
Значение меры — это произведение двух множителей:
- TF (term frequency) — частота слова во фразе.
- IDF (inverse document frequency) — число всех фраз в датасете, разделенное на число фраз с нужным словом. IDF слова повышается, если оно встречается в небольшом числе фраз. Если слово часто встречается во всех фразах датасета, то его IDF понижается.
Настройте параметры:
-
Привести все слова к нижнему регистру.
подсказкаЕсли в вашем датасете есть имена собственные, эта настройка может быть полезной, иначе Москва и москва будут считаться разными словами. -
Максимальная длина N-граммы — сколько слов из фразы будут объединены в словосочетания. Значение по умолчанию — 2.
-
Максимум пропущенных слов в словосочетании — сколько слов подряд можно пропустить во фразе, из которой формируются словосочетания. Например, в вашем датасете есть фраза Пожалуйста, больше никогда не звоните мне. Во время разметки из нее будут выделены такие словосочетания:
Значение параметра Результат 1 Пожалуйста, никогда не звоните
Больше не звоните мне2 Пожалуйста, не звоните мне
Никогда не звоните мне3 Пожалуйста, звоните мне Значение по умолчанию — 1. Не рекомендуется менять значение, поскольку смысл фразы может измениться.
-
Минимальная частота униграмм — сколько раз слово должно встречаться в датасете, чтобы оно учитывалось при поиске ключевых слов. Значение по умолчанию — 10. Рекомендуемое значение для средних датасетов (от 100 до 1 000 фраз) — 6–7, для крупных (от 1 000 фраз) — от 7 и выше.
-
Минимальная частота N-граммы — сколько раз словосочетание должно встречаться в датасете, чтобы оно учитывалось при поиске ключевых слов. Значение по умолчанию — 5. Рекомендуемое значение для средних датасетов (от 100 до 1 000 фраз) — 2–4, для крупных (от 1 000 фраз) — от 5 и выше.
-
Максимальное общее число N-грамм из фразы — сколько словосочетаний можно составить из одной фразы. Значение по умолчанию — 4. Рекомендуемое значение — 2–5, для длинных фраз — до 6–7.
Синтаксический метод
Метод позволяет определить синтаксическую связность слов во фразах с помощью парсера UDPipe. Он распознает синтаксические связи во фразах и размечает слова по частям речи.
Настройте параметры:
-
Язык.
предупреждениеМетод доступен только для русского, английского и китайского языков. -
Привести все слова к нижнему регистру.
-
Привести ключевые слова к словарной форме. Например, если включить параметр, то для фразы Пожалуйста, больше никогда не звоните мне будет выделено ключевое слово не звонить.
-
Сказуемое во фразах обязательно — будут выделены только фразы, в которых есть сказуемые.
По кластерам
Эта разметка позволяет выделить в датасете похожие фразы и объединить их в кластеры.
Методы кластеризации:
- Вероятностный на основе алгоритма K-means.
- Иерархический (Linkage) на основе метода Уорда.
Вероятностный метод
Алгоритм K-means распределяет фразы по заранее известному числу кластеров. Чтобы использовать его, нужно иметь представление о количестве кластеров, достаточном для датасета. Алгоритм сформирует ровно столько кластеров, сколько вы зададите, и сделает их максимально различными, насколько это возможно.
Суть алгоритма заключается в итеративном повторении двух шагов:
- Распределение фраз из датасета по кластерам.
- Перерасчет центров кластеров. Когда центры кластеров перестают меняться, алгоритм завершает работу.
Настройте параметры:
-
Язык.
предупреждениеМетод доступен только для русского, английского и китайского языков. -
Количество кластеров — на сколько групп разбить фразы. Просмотрите свой датасет и предположите, сколько в нем затрагивается тем, — это будет примерным количеством кластеров.
Иерархический метод
Алгоритм Linkage на основе метода Уорда распределяет фразы по кластерам. Задавать число кластеров не нужно — оно определяется автоматически.
Настройте параметры:
-
Язык.
предупреждениеМетод доступен только для русского, английского и китайского языков. -
Пороговое значение — параметр устанавливает максимально допустимое расстояние между кластерами. При расчете используется косинусная мера. Принимает значения от 0 до 1. Значение по умолчанию — 0.25.
подсказкаЧем больше значение параметра, тем меньше кластеров выделяется из датасета.Пример
Предположим, фразы в датасете делятся на две темы, т. е. на два кластера: один из них посвящен кредитам, другой — ипотеке. В датасете есть фразы, которые могут относиться к обоим кластерам в зависимости от значения параметра:
- Хочу взять кредит на первоначальный взнос для ипотеки.
- Я могу взять кредит, если у меня уже есть ипотека?
- Расскажите, как взять ипотечный кредит.
Во время кластеризации возможны такие результаты:
Значение параметра Результат 0.25 Каждая из фраз может образовать отдельный кластер. 0.35 Фразы № 1 и № 3 образовали кластер Расскажите, как взять ипотечный кредит, фраза № 2 в отдельном кластере. 0.45–0.55 Фразы № 1 и № 3 вошли в крупный кластер Взять ипотеку, фраза № 2 в отдельном кластере. 0.65 и выше Фразы № 1 и № 3 в крупном кластере Взять ипотеку, фраза № 2 вошла в крупный кластер Взять кредит. Многое зависит от вашего датасета, поэтому значение подбирается опытным путем.
-
Количество фраз для кластеризации — количество фраз, которые вы хотите обработать за раз. Настройка может быть полезна при работе с крупными датасетами. Если хотите обработать все фразы сразу, не меняйте значение параметра.
Разбор фраз
После того как вы разметили фразы, вы можете переключаться между размеченным контентом на вкладке Разбор фраз → раздел Результаты разметки:
-
Выберите любой результат разметки, например разметку по интентам. Слева находятся интенты, которые будут пополнены распознанными фразами, справа — сами фразы.
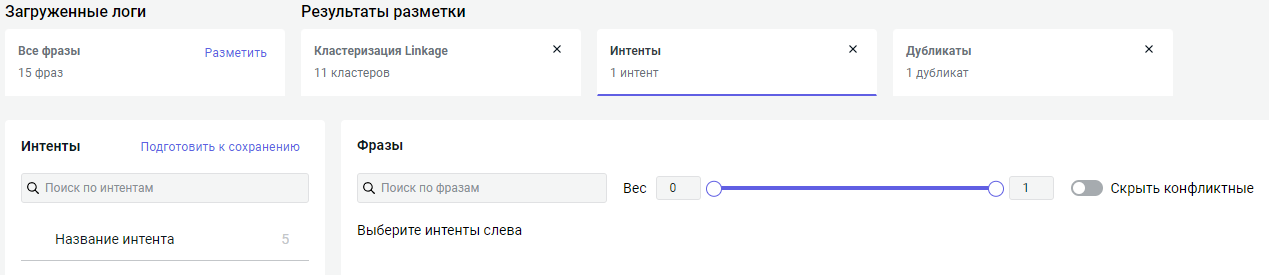
-
Просмотрите распознанные фразы. С помощью опции Скрыть конфликтные вы можете скрыть фразы, которые подходят к нескольким интентам.
подсказкаПолезно просматривать фразы, распознанные с низким весом, — среди них вы можете найти ложные срабатывания. Добавляйте такие фразы в другие, более подходящие интенты. Вы также можете увеличить пороговые значения интентов, чтобы фразы с низким весом распознавались реже. -
Если вас устроили результаты разметки, переходите к шагу 5.
-
Если некоторые фразы распознаны некорректно, вы можете их удалить или распределить по нужным интентам вручную. Для этого выберите фразы и нажмите Добавить в интенты. Появится окно выбора интента.
-
Выберите подходящий интент или создайте новый. После этого нажмите Добавить фразу.
-
Нажмите Подготовить к сохранению. Все распознанные фразы будут добавлены в интенты. Чтобы подтвердить изменения, перейдите на вкладку Сохранение в интенты.
подсказкаДля результатов разметки по кластерам, ключевым словам и дубликатам этот шаг пропускается. После добавления фраз в интенты сразу переходите на вкладку Сохранение в интенты.
Сохранение фраз в интенты
-
Выберите на верхней панели вкладку Сохранение в интенты. Здесь находятся все фразы, которые вы добавили в интенты во время разбора фраз.
-
Просмотрите дерево интентов: вы можете переключаться между интентами, удалять лишние фразы или добавлять их в другие интенты.
-
Нажмите Сохранить в интенты. После этого все фразы будут сохранены в выбранные интенты проекта.
-
На боковой панели перейдите в NLU → Интенты и нажмите Тестировать в правом нижнем углу, чтобы обучить классификатор на новом наборе фраз.