Algorithm comparison
General information
| How it works | Requires Caila connection | |
|---|---|---|
| Transformer ru | Uses logistic regression + embeddings optimized for Russian | Yes. Service: text-classifier-logreg-caila-roberta |
| Transformer multi | Uses logistic regression + multilingual embeddings for 109 languages | Yes. Service: text-classifier-logreg-labse |
| Deep Learning | Uses convolutional neural network + pre-trained BPEmb embeddings | No |
| Classic ML | Uses logistic regression + linguistic preprocessing | No |
| STS | Uses phrase similarity scoring | No |
Quality and performance
| Average accuracy | Model training speed | You can check why the intent was triggered | |
|---|---|---|---|
| Transformer ru | 80–90% | A few minutes for datasets with over 10,000 phrases | No |
| Transformer multi | 80–90% | A few minutes for datasets with over 10,000 phrases | No |
| Deep Learning | 75–85% | Long | No |
| Classic ML | 70–80% | Fast on datasets up to 5,000 phrases | No |
| STS | 65–75% | Very fast | The request mapping to the closest training phrase is available |
Number of phrases and thresholds
| Recommended intent threshold | Recommended number of phrases in an intent | Total number of phrases | The same number of phrases is required in intents | |
|---|---|---|---|---|
| Transformer ru | 0.3–0.5 | 10+ The larger the dataset, the more accurate the classification | Limited only by Caila memory | No |
| Transformer multi | 0.3–0.5 | 10+ The larger the dataset, the more accurate the classification | Limited only by Caila memory | No |
| Deep Learning | 0.4–0.7 | 50+ The larger the dataset, the more accurate the classification. See a possible solution for small datasets | No restrictions | No |
| Classic ML | 0.1–0.2 | 20+ The larger the dataset, the more accurate the classification | No restrictions | Might perform unpredictably if an intent’s phrase count deviates significantly from the average. See a possible solution |
| STS | 0.2–0.6 | 5–7+ The algorithm will function even if there is only one phrase in the intent | No more than 1000 | No |
Recommendations for phrase length
-
Recommended training phrase length: 1–10 words. Long phrases aren’t ideal for intent recognition because it’s harder to extract meaning from them.
-
If the bot is under heavy load, reduce the length and number of phrases in intents, or choose a classifier algorithm that can handle the load, such as Classic ML.
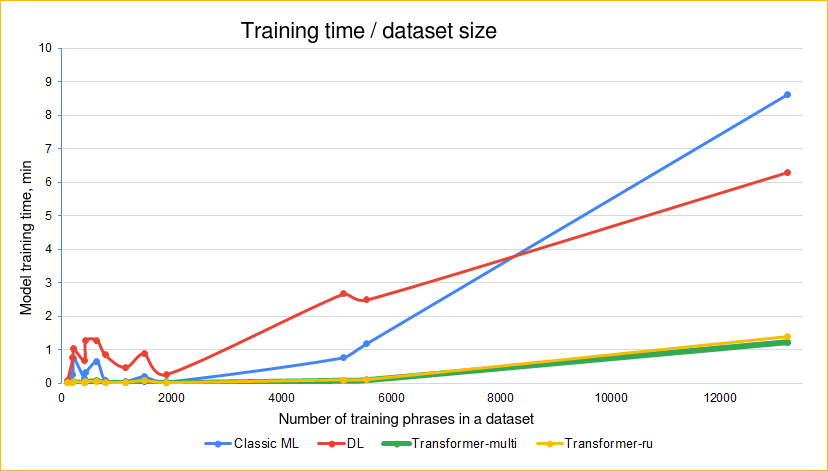
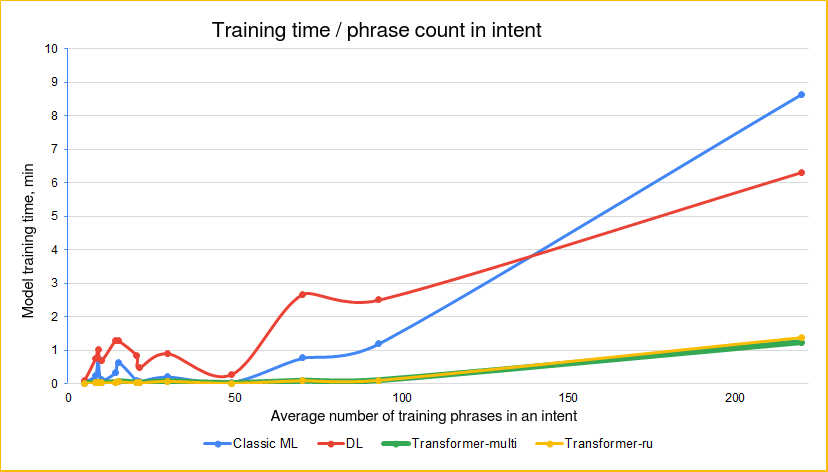
Impact of phrase count on training time
The Just AI team conducted an internal study to compare how quickly different classifiers train on datasets of various sizes.
The study used datasets with varying numbers of intents and training phrases. The data was in different languages.
-
Training time and number of phrases in the dataset:
-
Training time and average number of phrases per intent:
Impact of request length and phrase count on classification speed
| Speed depends on the client request length | Speed depends on the number of phrases in intents | |
|---|---|---|
| Transformer ru | No | No |
| Transformer multi | No | No |
| Deep Learning | No | No |
| Classic ML | No | No |
| STS | Yes | Yes |
Languages
| Languages | Multilingual support | Lemmas and stems | |
|---|---|---|---|
| Transformer ru | Optimized for Russian. Supports around 50 languages as well, with lower accuracy than Transformer multi | Yes, but for multilingual support we recommend using Transformer multi | Does not consider lemmas and stems, but compensates with embeddings |
| Transformer multi | Supports 109 languages | Yes | Does not consider lemmas and stems, but compensates with embeddings |
| Deep learning | All JAICP languages | You can set "lang" = "multi" | Uses subwords from BPEmb |
| Classic ML | Russian, English, Chinese, Portuguese | No | Stems:
|
| STS | All JAICP languages | No | Considers lemmas |
Text Analysis
| Semantics | Supports entities in training phrases | Identifying important words | Working with negative examples | |
|---|---|---|---|---|
| Transformer ru | Pretrained caila-roberta embeddings | No | Unknown. See a possible solution | Performs well |
| Transformer multi | Pretrained LaBSE embeddings | No | Unknown. See a possible solution | Performs very poorly with negative examples. See a possible solution |
| Deep learning | Pretrained BPEmb embeddings | No | Can theoretically identify them. See a possible solution | Performs poorly. See a possible solution |
| Classic ML | Not supported. See a possible solution | No | TF-IDF to determine word importance based on intent phrases. It is necessary to monitor the balance of secondary words in the dataset. See a possible solution | Performs well |
| STS | Built-in synonym dictionary for Russian only. Use the advanced NLU settings to adjust the algorithm for your project. For example, configure thesynonymMatch parameter to adjust the weight of synonym matches | Yes | Pretrained TF-IDF to determine word importance. The weights might not be relevant to your project topic | Performs well |
Text format
| Case sensitive | Considers punctuation | Distinguishes e and ё | |
|---|---|---|---|
| Transformer ru | Can be configured with toLowercase | Can be configured with doRemovePunctuations | In training phrases, but not in requests |
| Transformer multi | Can be configured with toLowercase | Can be configured with doRemovePunctuations | In training phrases, but not in requests |
| Deep learning | No | Yes | In training phrases, but not in requests |
| Classic ML | Can be configured with lower | No | In training phrases, but not in requests |
| STS | No | Yes | Yes |
Classifier behavior in complex cases
| Multi-label classification | Intents have similar phrases | Similar intents | |
|---|---|---|---|
| Transformer ru | No | Not recommended. Either one intent will receive a high weight, or the weight will be split between them. See a possible solution | Not recommended. See a possible solution |
| Transformer multi | No | Not recommended. Either one intent will receive a high weight, or the weight will be split between them | Not recommended. See a possible solution |
| Deep learning | No | Not recommended. Either one intent will receive a high weight, or the weight will be split between them | Intents will have equal weight, but that weight will be lower. See a possible solution |
| Classic ML | No | Not recommended. Both intents will have low weight for these phrases | The intents will have equal weight, but their weight will be lower. See a possible solution |
| STS | Yes | Acceptable, both intents will have equal weight | Acceptable, both intents will have equal weight |